Serveur HTTP minimaliste, x86-64 et IPv6
Divulgâchage : 224 octets pour faire un mini-serveur HTTP ? C’est tout à fait possible mais il faudra tout optimiser de partout…
Il y a quelques jours, je suis tombé sur un article intéressant d’Akanoa qui se demandait comment coder un serveur HTTP de moins de 20 Ko. Rien à voir avec le sloweb ; Akanoa déploie une application et a besoin qu’un programme tiers réponde un code 200 en HTTP pour que l’hébergeur considère que tout s’est bien passé.
Après moult péripéties où il explore les possibilités de langages
obscures, il fini par trouver la Lumière dans un code assembleur (x86)
qui répond en HTTP (en IPv4). Le binaire assemblé et lié fait
initialement 5Ko mais avec deux options passées à ld
(--omagic et --strip-all), il réduit
l’enveloppe à 376 octets et clôt son périple au pays de l’optimisation
des binaires.
Alors forcément, je n’ai pas pu m’empêcher de me demander ce que ça donnerait avec des technologies futuristes ; une architecture x86-64 et un réseau IPv6… Puis je me suis aussi demandé si on ne pouvait pas faire mieux que ld pour produire un binaire…
Divulgâchage : on peut faire mieux.
Premier code
Avant de chercher à tout optimiser aux petits oignons, on va d’abord écrire un premier code fonctionnel qui servira de référence. Le code qu’on vous propose ici est on ne peut plus classique et reprend les portions que nous avons publié dans Les shellcodes volume 1 :
- Un premier morceau qui gère le réseau et attend les connexions en TCP (cf. « bind shell », page 155),
- Un deuxième morceau qui envoie la réponse HTTP au correspondant (cf. « Envoyer 42 en UDP », page 123),
- Une boucle pour répondre à toutes les connexions entrantes (une étiquette et un saut).
Quitte à reprendre des morceaux, on aurait bien sûr pu compléter la réponse HTTP par l’envoi du contenu d’un fichier (cf. « Envoyer un fichier en UDP », page 135) et ainsi proposer un véritable serveur HTTP, mais ce n’est pas ce que cherche à faire Akanoa (il veut juste répondre un code 200) et ça aurait donc rallongé le binaire inutilement.
Pour ceux qui n’aiment pas lire l’assembleur directement, voici le traditionnel diagramme de flot correspondant à ce qu’on veut écrire. Les rectangles correspondent aux appels systèmes et leur enchaînement est traduit par des flèches pleines. Les parallélogrammes correspondent aux données et leur production et utilisation sont traduites par des flèches grises pointillées.
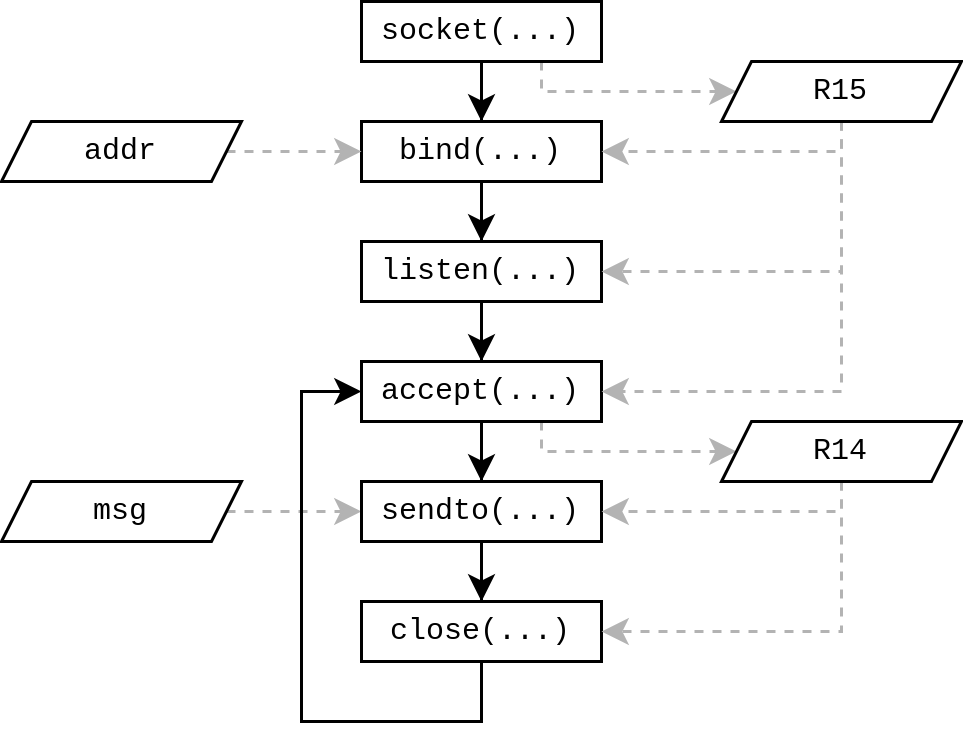
Pour rester au plus simple, les descripteurs de sockets seront placés
dans des registres et les données statiques (adresse d’écoute et réponse
HTTP) seront placées à la suite du code. Vu qu’on écrit un binaire et
pas un shellcode, on aurait pu placer ces données statiques dans une
section spécifique (i.e. la section .data) mais
comme on veut optimiser la taille du fichier, on va rester sur le style
shellcode et ainsi économiser une section.
Attention : Contrairement à l’article d’Akanoa qui utilise NASM, nous préférons utiliser gas et c’est donc la traditionnelle syntaxe AT&T que nous utilisons dans les codes qui suivent. Notez aussi les trois premières lignes qui permettent de produire un binaire (et pas uniquement un shellcode).
.section .text
.globl _start
_start:
socket:
mov $0x29, %rax # socket(
mov $10, %rdi # AF_INET6,
mov $0x01, %rsi # SOCK_STREAM,
mov $0x00, %rdx # 0
syscall # ) ;
mov %rax, %r15
bind:
mov $49, %rax # bind(
mov %r15, %rdi # sockfd,
lea addr(%rip), %rsi # *addr,
mov $addrlen, %rdx # addrlen
syscall # ) ;
listen:
mov $50, %rax # listen(
mov %r15, %rdi # sockfd,
mov $1, %rsi # backlog = 1
syscall # ) ;
loop:
accept:
mov $43, %rax # accept(
mov %r15, %rdi # sockfd,
mov $0x0, %rsi # *addr=0,
mov $0x0, %rdx # *addrlen=0
syscall # ) ;
mov %rax, %r14
sendto:
mov $44, %rax # sendto(
mov %r14, %rdi # sockfd,
lea msg(%rip), %rsi # buf,
mov $msglen, %rdx # len,
mov $0, %r10 # flags,
mov $0, %r8 # dest_addr,
mov $0, %r9 # addrlen
syscall # ) ;
close:
mov $3, %rax # close(
mov %r14, %rdi # fd
syscall # ) ;
jmp loop
addr:
.byte 0x0a, 0x00 # sin6_family = AF_INET6
.byte 0x90, 0x1f # sin6_port = 8080
.byte 0, 0, 0, 0 # flowinfo
.byte 0, 0, 0, 0, 0, 0, 0, 0 # sin6_addr 1/2 = IN6ADDR_ANY_INIT
.byte 0, 0, 0, 0, 0, 0, 0, 0 # sin6_addr 2/2
.byte 0, 0, 0, 0 # sin6_scope_id
addrlen = . - addr
msg:
.ascii "HTTP/1.0 200 OK\r\n"
.ascii "Content-length: 2\r\n"
.ascii "\r\n"
.ascii "Ok"
msglen = . - msgL’assemblage du fichier par gas ne pose pas de problème puisque nous
sommes dans le cas par défaut (x86-64). De même pour ld
puisque nous n’avons pas d’appel à des bibliothèques (le code ne fait
que des appels systèmes).
$ as http.s -o http.o
$ ld http.o -o httpEt puisque c’est la taille qui compte, on va maintenant la mesurer…
$ size -G http
text data bss total filename
236 0 0 236 http
$ du -b http
5200 http
$ du -h http
8,0K httpPour paraphraser les trois commandes précédentes… Cette première version se traduit en 236 octets d’instructions et données. Le fichier exécutable nécessite 5200 octets car il ajoute des informations d’en-têtes diverses. Et le système en utilise en réalité 8192 puisque le disque est alloué en pages atomiques de 4Kio.
Comme Akanoa, on va maintenant demander à ld de produire un binaire plus minimaliste en supprimant de l’inutile et mesurer l’économie ainsi réalisée.
$ ld http.o -o http --omagic --strip-all
ld: attention: http a un segment LOAD avec les permissions RWX
$ du -b http
568 httpOn a presque divisé la taille du fichier par 10 ce qui est plutôt pas mal. Notez que côté espace disque, ça occupe maintenant une seule page de 4096 octets mais on ne pourras pas faire moins. Les optimisations suivantes sont donc artistiques ; belles parce qu’inutiles.
Le tableau suivant résume les tailles (en octets) de la version 32 bits (& IPv4) et notre première version 64 bits (& IPv6). On prend plus de place, mais ce n’est pas vraiment une surprise.
| 32 bits & IPv4 | 64 bits & IPv6 | |
|---|---|---|
| Par défaut | 4756 | 5200 |
| omagic & strip-all | 376 | 568 |
| Instructions & données | 142 | 236 |
Optimisations du code
Maintenant qu’on a une base fonctionnelle, on va pouvoir s’amuser à modifier le code pour réduire la taille du binaire. Certaines optimisations sont générales et peuvent se faire dans n’importe quel code, d’autres sont plus spécifiques à notre cas particulier.
Supprimer les MOV inutiles
Par soucis pédagogique (ou de maintenance), nous avons utilisé une instruction MOV pour placer la valeur de chacun des paramètres des appels systèmes dans leurs registres respectifs. Certaines de ces instructions sont en fait inutiles car la valeur est déjà présente dans le registre cible (ou presque).
Zéro déjà présent
Lorsqu’un programme démarre, lorsque l’instruction de son point d’entrée est exécutée par le processeur, tous les registres sont à zéro (sauf RIP, RSP et autres registres spécifiques). On n’y pense pas avec les shellcodes car le programme hôte a déjà fait des opérations avant que le shellcode ne prenne la main. Mais puisque nous développons ici un programme, pouvons utiliser cette propriété pour optimiser notre code.
Lorsque aucune opération n’a modifié la valeur du registre avant qu’on veuille le mettre à zéro, l’opération est inutile et on peut donc l’enlever. Voici les MOV concernés dans noter programme :
- Dans le bloc
socket, à destination de RDX - Dans le bloc
sendto, à destination de R8, R9 et R10.
Supprimer ces 4 instructions nous permet d’économiser 28 octets (7 / instruction).
Valeur déjà présente
De même, il est inutile de placer une valeur lorsqu’elle est déjà présente dans un registre (parce qu’elle y a été placée et n’a pas été modifiée depuis). Voici les MOV concernés :
- Dans le bloc
listen(), l’identifiant de socket a déjà été placé dans RDI lors de l’appel système précédent (bind()), - Dans le bloc
close(), l’identifiant de socket du correspondant a été placé dans RDI lors de l’appel système précédent (sendto()).
Supprimer ces deux instructions nous permet d’économiser 14 octets de plus.
Valeur présente ailleurs
Parfois, la valeur qu’on veut placer dans le registre n’y est pas encore mais elle existe ailleurs ; dans un autre registre, dans la pile ou en mémoire. Voici les instructions concernées :
Dans le bloc socket(), mettre 1 dans RSI peut être
obtenu via la valeur de argc placée au sommet de pile par
le système (car notre programme est lancé sans argument autre que son
nom). Remplacer ce mov par un pop nous fait
économiser 6 octets :
mov $0x01, %rsi # 48 c7 c6 01 00 00 00
pop %rsi # 5eDans le bloc accept(), la mise à zéro des registres RSI
et RDX pourrait être obtenue via RBP qui, comme tous les registres qui
n’ont pas été modifié depuis le début, est à zéro. Nous pourrions aussi
remplacer cette instruction par un xor mais elle n’est pas
plus économique. Dans ces deux cas, nous économisons 4 octets par
instruction :
mov $0x0, %r10 # 49 c7 c2 00 00 00 00
mov %rbp, %r10 # 49 89 ea
xor %r10, %r10 # 4d 31 d2Valeur inutile
Dans certains cas, nous devons placer une valeur dans un registre mais cette valeur importe relativement peu. Tant qu’on reste dans des bornes acceptables, qu’importe la valeur, le programme répondra à nos attentes.
C’est le cas du deuxième paramètre de l’appel système
listen(2). Il spécifie la taille de la file d’attente pour
les requêtes entrantes. Tant que cette valeur est relativement
petite le noyau pourra s’en dépatouiller. Or, le registre
correspondant (RSI), contient à ce moment l’adresse de la structure
définissant l’adresse d’écoute (addr) qui, même si elle est
grande, ne l’est pas trop.
En supprimant cette instruction, on économise encore 7 octets.
Remplacer des MOV
Maintenant que nous avons supprimé les instructions MOV inutiles, voyons comment optimiser celles qui restent.
8 bits de valeurs, passer par la pile
Lorsqu’on écrit un shellcode, on utilise cette technique pour supprimer les octets nuls dans le binaire produit lorsque la valeur à déplacer est petite (cf. « Cachez ces zéros », page 345). Mais il se trouve qu’elle a aussi le bon goût de réduire la taille des instructions…
Concrètement, plutôt qu’utiliser une instruction de 7 octets pour déplacer notre petite valeur, on va le faire en deux instruction via la pile :
- Un « PUSH imm8 » car la valeur empilée est alors étendue sur 64 bits (en recopiant le bit de signe) ;
- Un « POP r64 » qui dépile cette valeur à destination d’un registre.
Le code suivant montre ce que donne cette technique sur le premier
mov du code dans l’appel à socket(2). Notez
que, contrairement à la tradition qui veut que chaque instruction soit
seule sur sa ligne, nous les avons regroupées par deux (séparées par un
point-virgule) pour mieux rendre la notion de groupes d’instructions qui
en remplacent une.
mov $0x29, %rax # 48 c7 c0 29 00 00 00
push $0x29 ; pop %rax # 6a 29 58Notez ensuite une petite subtilité de gas. Cet assembleur fonctionne en une seule passe ; si vos variables sont utilisées avant d’être définies, il les considère comme nécessitant 32 bits lorsqu’il écrit l’instruction puis viendra modifier la valeur une fois qu’il la connaîtra. Qu’importe qu’elle utilise en réalité 8 bits ou 16 bits, il ne reviendra pas en arrière pour modifier son instruction.
Par exemple, voici trois variantes de l’instruction qui place la
taille de l’adresse dans le troisième paramètre de l’appel système
bind(2). La première est celle non optimisée, la seconde
est optimisée mais conserve une valeur de 32 bits (la variable
$addrlen est définie après), la troisième utilise la valeur
sans passer par une variable. La traduction en hexadécimal en
commentaire vous montre comment ces instructions sont traduites par
gas.
mov $addrlen , %rdx # 48 c7 c2 1c 00 00 00
push $addrlen ; pop %rdx # 68 1c 00 00 00 5a
push $28 ; pop %rdx # 6a 1c 5aSur l’ensemble du code, on économise 4 octets pour chacun des MOV qui ciblent les 8 premiers registres, et 3 octets pour les 3 MOV qui ciblent les 8 derniers registres (R8 à R15) car ils nécessitent un préfixe REX.
32 bits de registres, en 32 bits
Lorsque les 32 bits de poids fort du registre de destination ont déjà la bonne valeur, il est inutile de déplacer les 64 bits du registre ; les 32 de poids faibles sont suffisants.
C’est le cas dans le block accept() où nous copions RBP
vers les registres RDI et RDX. Leurs 32 bits de poids forts sont déjà à
zéro (RSI contient l’adresse de addr qui tient sur 32 bits,
et RDI contient addrlen, soit 28). Nous pouvons donc
remplacer ces instructions 64 bits en 32 bits et conserver le même
résultat :
mov %rbx, %rdi # 48 89 df
mov %ebx, %edi # 89 dfLa copie dans R15 (en destination après l’appel à
socket() puis en source pour les appels à
bind(), listen()accept()) est un cas particulier. Ce registre faisant
partie des nouveaux, nous devons systématiquement utiliser le préfixe
REX pour l’identifier. Même si nous faisons une opération sur 32 bits,
le préfixe changera mais restera obligatoire. Nous allons donc remplacer
ce registre R15 par un autre qui n’est pas utilisé dans notre code ; RBX
(et donc EBX en 32 bits).
Voici les variantes et leur traduction en hexadécimal.
mov %rax, %r15 # 49 89 c7
mov %eax, %r15d # 41 89 c7
mov %rax, %rbx # 48 89 c3
mov %eax, %ebx # 89 c3
bind:
/* ... */
mov %r15, %rdi # 4c 89 ff
mov %ebx, %edi # 89 dfNous économisons ainsi 1 octet par instruction, soit 3 au total ici puisque nous avons une écriture et deux lectures. Nous verrons dans la section suivante comment en gagner 2 de plus.
Entre registres, par la pile
La copie dans R14 a le même problème ; nous ne pouvons pas garder
R14. Par contre, vu que nous n’avons qu’une écriture (après
accept()) et une lecture (dans sendto()), nous
pouvons passer facilement par la pile en remplaçant l’écriture par un
push et la lecture par un pop.
accept:
/* ... */
mov %rax, %r14 # 49 89 c6
push %rax # 50
sendto:
/* ... */
mov %r14, %rdi # 4c 89 f7
pop %rdi # 5fNous économisons ici 2 octets par instruction, soit 4 au total.
Nous pouvons maintenant utiliser cette technique pour gagner 2 octets dans la manipulation de l’identifiant de la première socket (stockée initialement dans R15 puis dans RBX).
Pour commencer, nous remplaçons l’écriture par un push
et la première lecture (dans l’appel à bind()) par un
pop. L’appel à listen() utilise aussi cet
identifiant mais il est dans le même registre et nous n’avons rien à
faire. Voici à qui ressemblent ces trois blocs à ce stade des
optimisations.
socket:
push $0x29 ; pop %rax # socket(
push $10 ; pop %rdi # AF_INET6,
pop %rsi # SOCK_STREAM,
# 0
syscall # ) ;
push %rax
bind:
push $49 ; pop %rax # bind(
pop %rdi # sockfd,
lea addr(%rip), %rsi # *addr,
push $28 ; pop %rdx # addrlen
syscall # ) ;
listen:
push $50 ; pop %rax # listen(
# sockfd,
# backlog = 1
syscall # ) ;L’appel à accept() nécessite plus d’attention. S’il
était seul, nous n’aurions rien à écrire puisque la valeur est déjà là
(depuis l’appel à bind()), mais nous sommes ici dans le
corps de la boucle principale. Lors de la deuxième itération, c’est
l’identifiant de la socket utilisée pour écrire le message (et
ensuite fermée) qui sera dans ce registre.
Nous devons donc récupérer la valeur de la première socket à chaque itération (à un moment où elle est sur le sommet de la pile). Et donc la placer au sommet de pile à chaque itération (à un moment où elle est dans un registre).
Le code suivant vous montre notre solution. La socket est sauvegardée juste après l’appel système et restaurée juste avant le saut vers l’itération suivante. Chaque itération commence donc avec la valeur de cette socket dans le bon registre (c’est un invariant de boucle). Voici cette partie du code à ce stade de nos optimisations.
loop:
accept:
push $43 ; pop %rax # accept(
# sockfd,
mov %ebp, %esi # *addr=0,
mov %ebp, %edx # *addrlen=0
syscall # ) ;
push %rdi
push %rax
sendto:
push $44 ; pop %rax # sendto(
pop %rdi # sockfd,
lea msg(%rip), %rsi # buf,
push $0x28 ; pop %rdx # len,
# flags,
# dest_addr,
# addrlen
syscall # ) ;
close:
push $3 ; pop %rax # close(
# fd
syscall # ) ;
pop %rdi
jmp loopNous utilisons ainsi 4 octets pour manipuler cet identifiant de
socket contre 6 avec trois mov utilisant EBX (ou 9
initialement avec R15). Ce n’est pas beaucoup, mais vu le peu d’octets
qu’ils reste, ça fait une différence.
Remplacer RIP par RCX dans LEA
Le code contient deux instructions LEA pour charger une adresse dans un registre. Parce que c’est bien pratique, cette adresse est calculée par rapport à RIP (c’est à dire par rapport à la prochaine instruction). Voici ces instructions et leur traduction en hexadécimal (à ce stade des optimisations) :
lea addr(%rip), %rsi # 48 8d 35 55 00 00 00
/* ... */
lea msg(%rip), %rsi # 48 8d 35 0d 00 00 00Comme vous pouvez le voir, les adresses relatives tiennent facilement sur 8 bits mais l’instruction en utilise 32. Et ce n’est pas la faute de gas qui utilise 32 bits partout mais une limitation de l’architecture ; l’adressage relatif à RIP a été ajouté sous forme d’exception dans l’octet ModR/M et seules les adresses de 32 bits sont prévues.
Dans un shellcode traditionnel, nous pourrions utiliser la
technique du jmp/call/pop (page 64 pour la version 64 bits
et page 96 pour la version 32 bits). Comme le montre le code suivant où
nous avons implémenté la technique, nous ajoutons 8 octets et n’en
économisons que 7, ce qui n’est pas rentable.
_start:
jmp data # eb 3c
start:
pop %rbx # 5b
/* bind() ... */
lea 0x28(%rbx), %rsi # 48 8d 73 28
/* sendto() ... */
mov %rbx, %rsi # 48 89 de
/* ... */
data:
call start # e8 bf ff ff ff
msg:
/* ... */On pourrait alors se tourner vers la technique du
call $+5 (page 70). Comme le montre le code suivant, elle
n’est pas rentable non plus car nous ajoutons 6 octets pour n’en
économiser que 6…
_start:
call start # e8 00 00 00 00
start:
pop %rbx # 5b
/* bind() ... */
lea 0x65(%rbx), %rsi # 48 8d 73 65
/* sendto() ... */
lea 0x3d(%rbx), %rsi # 48 8d 73 3d
/* ... */Le problème des techniques précédentes, c’est que nous gaspillons trop d’instructions pour obtenir une adresse dans un registre. Pouvons nous économiser cette phase ?
La réponse est oui, en exploitant les appels systèmes (page 73). Car
lors de chaque instruction syscall, le processeur copie
l’adresse de la prochaine instruction dans RCX. Ça permet au noyau de
revenir là où il a été appelé. Ça veut aussi dire que, dans noter code,
RCX contient en permanence l’adresse de l’instruction qui suit le
dernier syscall exécuté.
Tout ce qu’il nous faut, c’est calculer l’adresse relative de la
donnée et cette instruction après un syscall. Vous pourriez
le faire à la main mais voici comment procéder avec l’aide de
objdump. Commencez par écrire les instructions LEA avec une
adresse relative factice (i.e. 0xff), assemblez le
code avec as puis inspectez-le avec objdump
comme suit (les passages inutiles sont caviardés) :
$ as -o http-01.o http-01.s
$ objdump -d http-01.o
[...]
0000000000000000 <_start>:
[...]
7: 0f 05 syscall
9: 50 push %rax
000000000000000a <bind>:
[...]
e: 48 8d 71 ff lea 0xff(%rcx),%rsi
[...]
000000000000003c <addr>:
[...]Dans l’appel à bind(), l’instruction lea a
besoin de connaître la distance entre l’adresse réseau (en
0x3c) et l’instruction qui suit le précédent
syscall (le push en 0x09). Elle
vaut donc 0x3c - 0x09 = 0x33.
Un calcul similaire permet d’obtenir l’adresse relative du message
(en 0x58) par rapport à l’adresse suivant le dernier
syscall (le push %rdi du block
accept(), en 0x25) et d’obtenir 0x33 (c’est
une coïncidence).
On économise alors 3 octets par instruction lea sans
besoin d’ajout d’instructions supplémentaires.
Code final
Voici le code une fois toutes ces optimisations faites :
.section .text
.globl _start
_start:
socket:
push $0x29 ; pop %rax # socket(
push $10 ; pop %rdi # AF_INET6,
pop %rsi # SOCK_STREAM,
# 0
syscall # ) ;
push %rax
bind:
push $49 ; pop %rax # bind(
pop %rdi # sockfd,
lea 0x33(%rcx), %rsi # *addr,
push $28 ; pop %rdx # addrlen
syscall # ) ;
listen:
push $50 ; pop %rax # listen(
# sockfd,
# backlog = 1
syscall # ) ;
loop:
accept:
push $43 ; pop %rax # accept(
# sockfd,
mov %ebp, %esi # *addr=0,
mov %ebp, %edx # *addrlen=0
syscall # ) ;
push %rdi
push %rax
sendto:
push $44 ; pop %rax # sendto(
pop %rdi # sockfd,
lea 0x33(%rcx), %rsi # buf,
push $0x28 ; pop %rdx # len,
# flags,
# dest_addr,
# addrlen
syscall # ) ;
close:
push $3 ; pop %rax # close(
# fd
syscall # ) ;
pop %rdi
jmp loop
addr:
.byte 0x0a, 0x00 # sin6_family = AF_INET6
.byte 0x1f, 0x90 # sin6_port = 8080
.byte 0, 0, 0, 0 # flowinfo
.byte 0, 0, 0, 0, 0, 0, 0, 0 # sin6_addr 1/2 = IN6ADDR_ANY_INIT
.byte 0, 0, 0, 0, 0, 0, 0, 0 # sin6_addr 2/2
.byte 0, 0, 0, 0 # sin6_scope_id
msg:
.ascii "HTTP/1.0 200 OK\r\n"
.ascii "Content-length: 2\r\n"
.ascii "\r\n"
.ascii "Ok"Le tableau suivant reprend les tailles précédentes et ajoute une colonne avec notre version optimisée. Nous avons fait mieux pour les instructions et leurs données, mais le programme complet reste plus grand que la version 32 bits…
| 32 bits & IPv4 | 64 bits & IPv6 | Optim. Code | |
|---|---|---|---|
| Par défaut | 4756 | 5200 | 5088 |
| omagic & strip-all | 376 | 568 | 464 |
| Instructions & données | 142 | 236 | 128 |
Optimiser l’exécutable
Les en-têtes du fichier
Puisque c’est la taille du binaire qui compte, et pas celle des instructions et leurs données, on va maintenant s’attaquer à réduire la taille du fichier ELF. Un peu comme ce que ld a fait lorsqu’on lui a passé les deux options, mais à la main, et en bien plus drastique…
L’idée est de créer l’en-tête ELF Minimale qui ne comprendra donc qu’une en-tête de fichier suivie d’une en-tête de [section de] programme. La création n’est pas très compliquée, il suffit de suivre la documentation officielle…
En-tête ELF
Cette première partie de 64 octets (soit 0x40 en hexadécimal) contient des champs permettant d’identifier le fichier comme étant un fichier ELF 64 bits exécutable et autres détails pratiques pour le système. Entre autre : trouver où sont les prochains en-têtes de sections.
Voici son contenu où nous avons mis, en commentaire, le nom du champ officiel suivi d’une description ou de la valeur (suivant lequel est le plus intéressant d’après nous).
# https://refspecs.linuxbase.org/elf/gabi4+/ch4.eheader.html
.byte 0x7f, 'E', 'L', 'F' # Signature ELF
.byte 2 # EI_CLASS : Objet 64 bits
.byte 1 # EI_DATA : petit boutiste
.byte 1 # EI_VERSION : 1
.byte 3 # EI_OSABI : Linux
.byte 0 # EI_ABIVERSION : 0
.fill 7, 1, 0 # EI_PAD : Bourrage
.2byte 2 # e_type : exécutable
.2byte 62 # e_machine : AMD x86-64
.2byte 1, 0 # e_version : 1
.8byte 0x100078 # e_entry : Point d'entrée
.8byte 0x40 # e_phoff : table des programmes
.8byte 0 # e_shoff : table des sections
.4byte 0 # e_flags : aucun drapeau
.2byte 0x40 # e_ehsize : taille de l'en-tête
.2byte 0x38 # e_phentsize : taille en-tête programme
.2byte 1 # e_phnum : 1 programme
.2byte 0 # e_shentsize : taille en-tête section
.2byte 0 # e_shnum : 0 sections
.2byte 0 # e_shstrndx : table des nom de sectionsLa plupart des champs n’ont pas besoin d’explication car il suffit de lire la documentation (et souvent ça se borne ensuite à choisir la valeur qu’on veut dans la liste). Mais les champs suivants nous paraissent utiles à préciser :
- e_entry : C’est l’adresse du point d’entrée dans le programme lorsqu’il sera chargé en mémoire. Cette valeur dépend donc de l’adresse de la section de code qui est définie dans la suite.
- e_phoff : Adresse relative de la table des programmes par rapport au fichier. Cette en-tête ELF fait 0x40 octets et est immédiatement suivie par la table des programmes.
- e_ehsize : Taille de cet en-tête ELF. Vous pouvez refaire les calculs, elle fait 0x40 octets.
- e_phentsize : Taille de l’en-tête de programme (c’est à dire des éléments dans la table des programmes). C’est la taille de la section qui va suivre.
En-tête de la section de programme
Sans réelle surprise, les données qui suivent concernent la table des programmes, c’est à dire la liste des en-têtes qui décrivent les sections du programme. Ici nous n’avons qu’une seule section dont voici la valeur :
# https://refspecs.linuxbase.org/elf/gabi4+/ch5.pheader.html
.4byte 1 # p_type : exécutable
.4byte 0x7 # p_flags : RWX
.8byte 0x78 # p_offset : offset dans le fichier
.8byte 0x100078 # p_vaddr : @ où maper le segment
.8byte 0 # p_paddr : @ physique (inutile)
.8byte 0 # p_filesz : taille segment dans le fichier
.8byte 0 # p_memsz : taille segment en mémoire
.8byte 0x100 # p_align : alignementPour mieux les comprendre, voici les valeurs qui nous concernent :
- p_flags : donne les droits d’accès à cette section en mémoire, nous pourrions ne demander que lecture et exécution mais tant qu’à y être, autant ajouter l’exécution (comme ça on pourra s’en servir pour d’autres programmes qui s’auto-modifient).
- p_offset : adresse relative dans le fichier vers le début des données de la section. Le premier en-tête fait 0x40 octets, celui-ci en fait 0x38 et il n’y a rien de plus avant le contenu de la section. Elle se trouve donc à 0x78 octets du début du fichier.
- p_vaddr : adresse virtuelle où charger le contenu de la section en mémoire. On peut y mettre presque tout ce qu’on veut. Pas 0 parce que le noyau n’apprécie pas, et pas de valeur trop grande car on a utilisé cette adresse comme « nombre de connexions dans la file d’attente » (cf. optimisation précédentes). On trouve souvent quelque chose à partir de 0x400000 mais on a choisi ici une valeur plus petite. Attention, l’adresse doit être alignée avec celle des données dans le fichier (d’où le 78 à la fin).
- p_filesz et p_memsz : donne la taille de la section (dans le fichier et dans la mémoire) mais peuvent être laissés à zéro (et le noyau prend le reste du fichier et se débrouille pour la calculer).
- p_align : valeur avec laquelle calculer les alignement précédents.
Vous pouvez faire les calculs, cet en-tête de programme fait bien 0x38 octets de long.
Produire le binaire
Pour construire l’exécutable, il faut copier ces en-têtes juste avant le code et les données. Il y a plusieurs manières de procéder ; en assembleur dans un fichier, dans plusieurs, en hexadécimal, en binaire, …
Puisqu’on a
déjà un makefile pour produire des shellcodes, nous avons
décidé de séparer l’en-tête et le code dans deux fichiers, d’assembler
chacun (avec as) et d’extraire les contenus individuels (avec
objcopy) puis de les concaténer (avec cat). Voici les trois
recettes pour y arriver.
%.o: %.s
as $< -o $@
%.raw: %.o
objdump -j .text -O binary $< $@
%: header.raw %.raw
cat $^ > $@
chmod a+x $@Il n’y a ensuite plus qu’à produire le binaire et mesurer sa taille.
$ make http
as -o http.o http.s
objcopy -j .text -O binary http.o http.raw
as -o header.o header.s
objcopy -j .text -O binary header.o header.raw
cat header.raw http.raw > http
chmod a+x http
rm http.o header.raw header.o
$ du -b http
248 httpOn et ainsi passé de 568 octets à 248 octets, c’est moins que les 376 de référence en 32 bits et IPv4. On pourrait donc s’arrêter ici mais j’avais envie d’aller un peu plus loin…
Utiliser les zéros des pages initialisées
Cette dernière optimisation part du constat que les pages mémoires sont initialisées à zéro avant d’y inscrire quoi que ce soit. Si le fichier copié en mémoire se termine par des zéro, il est donc inutile de les copier. Et donc inutile de les écrire dans le fichier…
Et c’est justement le cas de la structure contenant l’adresse d’écoute de la socket. Mis à part ses 4 premiers octets qui contiennent des valeurs (2 octets pour la famille d’adresse, puis 2 pour le numéro de port), les 24 suivants sont tous à zéro.
Nous pouvons donc mettre cette structure à la fin du fichier et
n’inscrire que les 4 premiers octets. Nous ne pouvons donc plus faire
calculer la taille de la structure à gas mais ce n’est pas
grave puisque cette taille est fixe (elle fait toujours 28 octets) et
nous l’avions de toutes façon déjà codée en dur en optimisant nos
mov par des push/pop.
Voici à quoi ressemble alors la fin du fichier. Le message est avant, l’adresse est après et tronquée.
msg:
/* ... */
addr:
.byte 0x0a, 0x00 # sin6_family = AF_INET6
.byte 0x1f, 0x90 # sin6_port = 8080
# flowinfo
# sin6_addr 1/2 = IN6ADDR_ANY_INIT
# sin6_addr 2/2
# sin6_scope_idAttention : puisque ces données ont été déplacées, il faut recalculer leurs adresses relatives utilisées dans les instructions LEA.
Nous pouvons construire cette nouvelle version et mesurer sa taille, on obtient alors 224 octets (24 de moins que la version précédente). C’est moins aussi que la version optimisée sur github de laquelle Akanoa s’était inspiré (elle fait 229 octets).
Et après ?
Individuellement, nous ne pouvons plus réduire les différentes parties de ce programme. L’en-tête ELF et l’en-tête du programme sont les plus petites possibles et je ne vois pas comment écrire le code assembleur du serveur HTTP avec moins. On pourrait donc croire que 224 octets et la limite minimum pour écrire un serveur HTTP minimaliste.
Il est en fait possible de faire mieux mais pour ça, il faudrait superposer les parties du programme les unes sur les autres (ce qu’on appelle du golfing). Un même octet du fichier pourra alors avoir plusieurs significations suivant qu’il est lu en tant qu’en-tête ELF, en-tête de programme ou instruction à exécuter. Les octets ainsi superposés sont autant d’économies réalisées… C’est passionnant mais c’est une autre histoire.
D’autant que si on revient au problème initial posé par Akanoa, rien ne nous oblige à écrire un code binaire…
Je veux […] quelque chose qui réponde en HTTP le plus léger possible et qui a le moins de dépendance également.
Akanoa
Si le but est d’avoir le fichier le plus petit et avec le moins de dépendances, un script bash est bien plus adapté. Car il évite la dépendance à une chaîne de compilation, réalise plus de choses avec moins de caractères et, en n’utilisant que des commandes UNIX, peut être exécuté partout.
Voici un exemple de serveur HTTP minimaliste en bash :
#!/bin/bash
while true ; do
echo -en "HTTP/1.0 200 OK\r\nContent-length: 2\r\n\r\nOk" \
| nc -l localhost 31337
doneIl fait 120 octets et on n’a même pas cherché à l’optimiser…