Minimalistic HTTP Server, x86-64 and IPv6
Spoiler: 224 bytes for a mini-HTTP server? Challenge accepted, but we'll need to optimize everything.
Some days ago, I read a nice and interresting article from Akanoa where he asked himself how to code a minimalistic HTTP server in less than 20KB. Nothing related to the sloweb movement; Akanoa is deploying an app and need another software to answer an 200 OK status code in HTTP to its host so it knows everything went well.
After numerous adventures exploring the possibilities of obscures languages, he finally got illuminated by an assembly code (x86) answering in HTTP (via IPv4). The binary code assembled and linked uses initially 5KB that he managed to cut down to 376 bytes with two ld’s options (--omagic and --strip-all) which end its journey in the land of binaries optimisations.
So, I inevitably asked myself how one could travel the same path with some really futuristic technologies; that is x86-64 architecture and IPv6... Then I asked myself if one could produce a smaller binary than than the one produced by ld...
Spoiler: we can make it smaller.
First code
Before searching to find optimisation everywhere, we’ll begin by writing a first functional code. That code will be used as a reference point. The following code is a classical one, reusing snippet of code we’ve published in our book Shellcodes, Volume 1:
- A first part that deal with the network and wait for TCP connections (cf. « bind shell », page 155),
- A second part that send back an HTTP message to the client (cf. « Send 42 through UDP », page 123),
- A loop that answer all incoming connections (with a label and a jump).
As we are reusing parts of shellcodes, we could have complmeted the HTTP response with the content of a file (cf. « Send a file through UDP », page 135) and thus propose a true HTTP server. But this is not the Akanoa’s target (he only want to answer a 200 OK status code) and this would have uselessly enlarged the binary.
For those who don’t like to read assembly code on the spot, here is our traditional flow diagram describing what we want to write. The rectangle describe system calls and their succession is rendered as black full arrows. Parallelograms describes data and their production and consumption is rendered by grey dotted arrows.
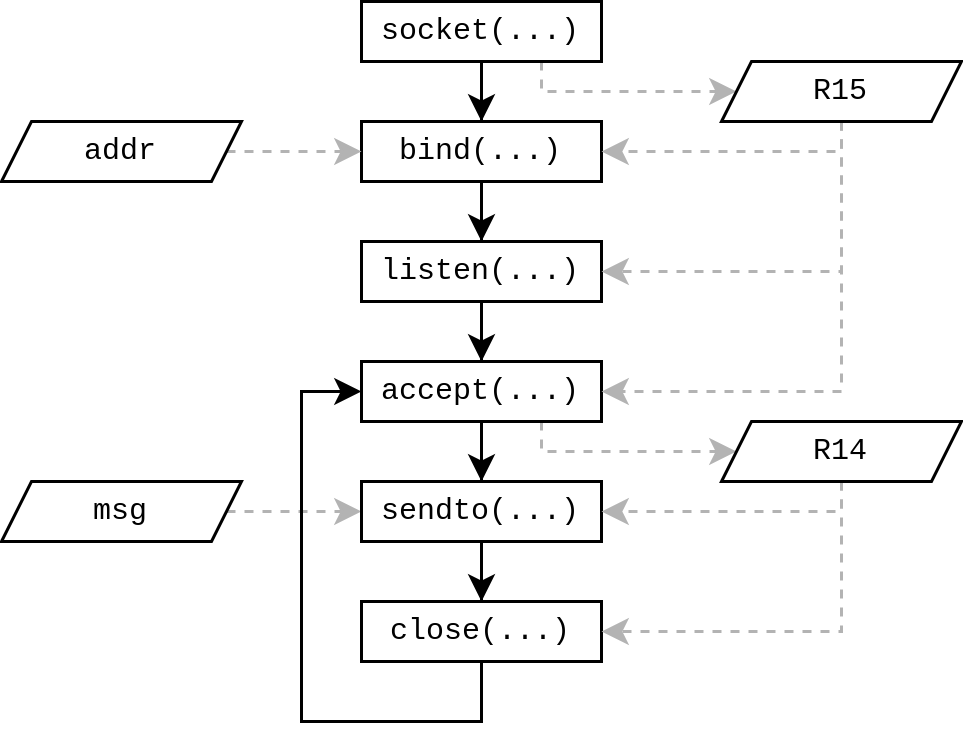
To keep it simple, the socket handles will be placed in registers and the static datas (binding address and HTTP response) will be placed next to the instructions. Since we are writing a software and not only a shellcode, we could’ve placed the data in their own section (e.g. the .data) but because we’re trying to optimize the size of the binary, we’ll keep the shellcode way of life, saving a section.
Beware: unlike Akanoa who’s using NASM, we prefer using gas and we’ll therefore use the traditional AT&T syntax in the following codes. Note also the three first lines that allows to produce an executable binary (and not only a shellcode).
.section .text
.globl _start
_start:
socket:
mov $0x29, %rax # socket(
mov $10, %rdi # AF_INET6,
mov $0x01, %rsi # SOCK_STREAM,
mov $0x00, %rdx # 0
syscall # ) ;
mov %rax, %r15
bind:
mov $49, %rax # bind(
mov %r15, %rdi # sockfd,
lea addr(%rip), %rsi # *addr,
mov $addrlen, %rdx # addrlen
syscall # ) ;
listen:
mov $50, %rax # listen(
mov %r15, %rdi # sockfd,
mov $1, %rsi # backlog = 1
syscall # ) ;
loop:
accept:
mov $43, %rax # accept(
mov %r15, %rdi # sockfd,
mov $0x0, %rsi # *addr=0,
mov $0x0, %rdx # *addrlen=0
syscall # ) ;
mov %rax, %r14
sendto:
mov $44, %rax # sendto(
mov %r14, %rdi # sockfd,
lea msg(%rip), %rsi # buf,
mov $msglen, %rdx # len,
mov $0, %r10 # flags,
mov $0, %r8 # dest_addr,
mov $0, %r9 # addrlen
syscall # ) ;
close:
mov $3, %rax # close(
mov %r14, %rdi # fd
syscall # ) ;
jmp loop
addr:
.byte 0x0a, 0x00 # sin6_family = AF_INET6
.byte 0x90, 0x1f # sin6_port = 8080
.byte 0, 0, 0, 0 # flowinfo
.byte 0, 0, 0, 0, 0, 0, 0, 0 # sin6_addr 1/2 = IN6ADDR_ANY_INIT
.byte 0, 0, 0, 0, 0, 0, 0, 0 # sin6_addr 2/2
.byte 0, 0, 0, 0 # sin6_scope_id
addrlen = . - addr
msg:
.ascii "HTTP/1.0 200 OK\r\n"
.ascii "Content-length: 2\r\n"
.ascii "\r\n"
.ascii "Ok"
msglen = . - msgThere is no difficulty in using gas to assemble this file into an object file because we are in the default case (x86-6). And neither difficulties with ld to link that file and build an executable binary for we use no library (the code only does system calls).
$ as http.s -o http.o
$ ld http.o -o httpAnd since only size matters, we’ll measure it...
$ size -G http
text data bss total filename
236 0 0 236 http
$ du -b http
5200 http
$ du -h http
8,0K httpTo paraphrase the previous commands... This first version is translated into 236 bytes of instructions and data. The executable file uses 5200 bytes because it adds lots of headers and informations. And the file system uses 8192 bytes because the disk is divided into atomic pages of 4KiB.
As Akanoa did, we’ll then ask ld to produce a smaller binary by deleting the useless parts and then measure the saving we’ve done.
$ ld http.o -o http --omagic --strip-all
ld: warning: http has a LOAD segment with RWX permissions
$ du -b http
568 httpWe’ve almost divided the file’s size by 10 which is pretty cool. Note that concerning the disk space, the file now uses a single page of 4096 bytes and we therefore won’t be able to use less. The next optimizations are thus artistic: being beautifull for being useless.
The next table summarize the size (in bytes) of the 32 bits (& IPv4) variant and our first 64 bits (& IPv6) variant. We take more place but it’s not a surprise.
| 32 bits & IPv4 | 64 bits & IPv6 | |
|---|---|---|
| Default | 4756 | 5200 |
| omagic & strip-all | 376 | 568 |
| Instructions and data | 142 | 236 |
Code Optimization
Now we have a functional base, we’ll be able to have fun changing the code to reduce its size in the binary file. Some optimizations are for general purpose and can be done in any code, some other are more specific to our particular case.
Deleting the useless MOV
For the purpose of pedagogy (or maintenance), we’ve use a MOV instruction to place all the values in the registers used for syscall parameters. Some of them are indeed useless because the value is already present in the register (or almost).
Zero already present
When a software is launched, when the first instruction at its entry point is executed by the processor, every register contains a zero (except RIP, RSP and other specific registers). We don’t think about it when writing a shellcode because the vulnerable software have already done some operation on them before our injection takes control of the processor. But since we are writing a full software, we can use this property to optimize our code.
When no operation have change the register value before we want to put a zero in it, the operation is useless and we can remove it. Here are all the MOV we can get rid of:
- In the
socketblock, into RDX, - In the
sendtoblock, into R8, R9 and R10.
Deleting those 4 instructions will save 28 bytes (7 per instruction).
Value already present
In the same way, it is useless to place a value when it is already in the register (because it have been placed here and never changed in between). Here are the MOV we are talking about:
- In the
listenblock, the socket handle have already been put here for the last system call (bind()), - In the
closeblock, the socket handle have been put in RDI for the previous system call (sendto()).
Deleting those two instructions save us 14 bytes more.
Value present elsewhere
Sometimes, the value we want to put in a register is not yet in that register but already exists elsewhere; in another register, in the stack or in memory. Here are the instruction we can change.
In the socket block, putting a 1 in RSI can be done through the argc program parameter, placed on the top of the stack by the system (for our programm is launched without arguments other than its name). Replacing this mov by a pop save us 6 bytes:
mov $0x01, %rsi # 48 c7 c6 01 00 00 00
pop %rsi # 5eIn the accept block, the zeroing of RSI and RDX can be done through RBP for it already contains a zero (since the start of the program). We could also replace this instruction with a xor that also save 4 bytes:
mov $0x0, %r10 # 49 c7 c2 00 00 00 00
mov %rbp, %r10 # 49 89 ea
xor %r10, %r10 # 4d 31 d2Useless value
In some cases, we must place a value in a register but the value itself is not so important. Provided we use a value between acceptable range, the value does not matter and the program will behave as expected.
It’s the case of the second parameter ofthe listen() system call. This parameter tells the size of the queue containing the incoming connections. Provided this value is relatively small, the kernel will be able to handle it. Well the corresponding register (RSI) already contains the address in memory of the structure that defines the listening network address (addr) which, despite being big, is not too much.
Deleting this instruction save 7 bytes more.
Replacing some MOV
Now we’ve deleted the useless ones, let’s see how to optimize the remaining ones.
8 bits value, through the stack
When we write a shellcode, we use this technique to remove null bytes in the binary when the moved value is short (cf. page 345 of the book). Now this technique is also good at reducing the instruction length...
Technically speaking, instead of 7 bytes to move our small value, we’ll do this in two steps:
- A « PUSH imm8 » for this pushed value is completed to make 64 bits (copying the sign bit),
- A « POP r64 » which takes back the 64bits value in the specified register.
The following code show you the result of this technique on the first mov of the socket block. Note that, contrary to the tradition which write one instruction on each line, we’ve written two of them in the same line (separated by a semi colon) to better render this notion of group of instruction replacing one instruction.
mov $0x29, %rax # 48 c7 c0 29 00 00 00
push $0x29 ; pop %rax # 6a 29 58Note then a gas subtlety. This assembler work in one pass and if your variable are used before being defined, gas consider they take 32 bits when writing instruction and will replace them by their value when it will know them. Whichever true size, being 8 bits or 16 bits, gas won’t change the instruction chosen and will keep the 32 bits version.
For instance, here are three variations of the instruction that place the network address size in the third parameter of the bind() system call. The first one is non optimized, the second is optimized but use a 32 bits value (the $addrlen variable is defined afterwards), the third uses the value without any variable. The hexadecimal translation (in comment) shows you how those instructions are translated by gas.
mov $addrlen , %rdx # 48 c7 c2 1c 00 00 00
push $addrlen ; pop %rdx # 68 1c 00 00 00 5a
push $28 ; pop %rdx # 6a 1c 5aIn the overall code, we save 4 bytes for every MOV that target the first 8 registers, and save 3 bytes for the other MOV that tarket the 8 last registers (R8 to R15) for they need a REX prefix to identify those registers.
32 bits values, 32 bits registers
When the 32 most significant bits of the target register already contain the intended value, it’s useless to move all 64 bits. We can restrict ourselves to move only the 32 least significant bits.
This is the case in the accept block where we’ve copied the RBP zero into the RDI and RDX registers. Their 32 most significant bits are already zeros (RSI contains the memory address of addr which only need 32 bits, and RDI contains addrlen that is 28). We can then replace those 64 bits instructions with their 32 bits variant and keep the same effect.
mov %rbx, %rdi # 48 89 df
mov %ebx, %edi # 89 dfThe copy with R15 (as the destination in the socket block, then as the source in the bind, listenaccept blocks) is a particular case. This register being one of the height news registers, we always need a REX prefix to identify this register. Even if we are using a 32 bits operation, the prefix will change a little but it will remain needed. We’ll then need to replace this R15 register with another one that is not already used in the code; RBX for instance (and thus EBX for the 32 bits operation).
Here is the instruction variation and their hexadecimal translations.
mov %rax, %r15 # 49 89 c7
mov %eax, %r15d # 41 89 c7
mov %rax, %rbx # 48 89 c3
mov %eax, %ebx # 89 c3
bind:
/* ... */
mov %r15, %rdi # 4c 89 ff
mov %ebx, %edi # 89 dfThis help us to save 1 byte per instruction, so a total amount of 3 bytes because we have one for writing in the register and then two to reading from this register. We’ll see in the next section how to save 2 more bytes.
Between registers, through the stack
The copy with R14 has the same problem: we can not keep R14. But this time, we only need one writing (just after the accept block) and one reading (in the sendto block), we can then use the stack to store (with a push) and then retrieve the value (with a pop).
accept:
/* ... */
mov %rax, %r14 # 49 89 c6
push %rax # 50
sendto:
/* ... */
mov %r14, %rdi # 4c 89 f7
pop %rdi # 5fWe save here 2 more bytes per instruction, so 4 bytes in total.
And we can now use this technique to save 2 bytes when manipulating the first socket handle (stored initialy in R15 and now in RBX).
We start with the replacement of the writing by a push and the first reading (in the bind block) with a pop. The next call to listen() also use this handle but it’s already in the needed registrer so we don’t need to copy it twice. Here is how those three blocks look like at this step of optimisation:
socket:
push $0x29 ; pop %rax # socket(
push $10 ; pop %rdi # AF_INET6,
pop %rsi # SOCK_STREAM,
# 0
syscall # ) ;
push %rax
bind:
push $49 ; pop %rax # bind(
pop %rdi # sockfd,
lea addr(%rip), %rsi # *addr,
push $28 ; pop %rdx # addrlen
syscall # ) ;
listen:
push $50 ; pop %rax # listen(
# sockfd,
# backlog = 1
syscall # ) ;The call to accept() need more care. If it was the only one, we won’t need to write anything because the value is already there (since the call to bind()). But we are in the body of the main loop. At the second iteration, the register will contain the handle of the socket used to write the message (and closed since then).
We therefore need to get the handle of the first socket back at every iteration (at a point where it is on the top of the stack). So we also need to place the handle in the top of the stack at every iteration (at a point where the value is in a register).
The following code shows our solution. The socket is saved just after the system call and put back just before the jump to the next iteration. That way, we begin every iteration with the handle value in the right register (it’s a loop invariant). Here is how the code look like at this step of optimisation.
loop:
accept:
push $43 ; pop %rax # accept(
# sockfd,
mov %ebp, %esi # *addr=0,
mov %ebp, %edx # *addrlen=0
syscall # ) ;
push %rdi
push %rax
sendto:
push $44 ; pop %rax # sendto(
pop %rdi # sockfd,
lea msg(%rip), %rsi # buf,
push $0x28 ; pop %rdx # len,
# flags,
# dest_addr,
# addrlen
syscall # ) ;
close:
push $3 ; pop %rax # close(
# fd
syscall # ) ;
pop %rdi
jmp loopWe now use 4 bytes to manipulate this handle, compared to 6 bytes with three mov using EBX (or 9 bytes initialy). This is not a lot, but there does not remain so much so it makes a difference.
Replace RIP with RCX in LEA
This code contains two LEA instructions to load a memory address in a register. Because it quite handy, this addess is computed relative to RIP (that is relative to the address of the next instruction). Here are those two instruction and their translations in hexadecimal (at this stop of optimisation):
lea addr(%rip), %rsi # 48 8d 35 55 00 00 00
/* ... */
lea msg(%rip), %rsi # 48 8d 35 0d 00 00 00As you can see, the relative addresses could be shortened in 8 bits (1 byte) but the instruction is using 32 bits (4 bytes). And this is not because of gas which would be using 32 bits everywhere but a limitation of the architecture: the use of RIP as the base address have been added as a kind of exception in the ModR/M byte and only 32 bits addresses are available.
In a traditional shellcode, we could use the jmp/call/pop technique (page 64 for the 64 bits version and page 96 for the 32 bits version). As shown in the following code, where we’ve implemented the technique, we’ve added 8 bytes and only save 7 (which add 1 byte in total), there is no profit.
_start:
jmp data # eb 3c
start:
pop %rbx # 5b
/* bind() ... */
lea 0x28(%rbx), %rsi # 48 8d 73 28
/* sendto() ... */
mov %rbx, %rsi # 48 89 de
/* ... */
data:
call start # e8 bf ff ff ff
msg:
/* ... */We could then move on the call $+5 technique (page 70). As shown in the following code, there is no profit either because we’ve added 6 bytes to save 6 bytes…
_start:
call start # e8 00 00 00 00
start:
pop %rbx # 5b
/* bind() ... */
lea 0x65(%rbx), %rsi # 48 8d 73 65
/* sendto() ... */
lea 0x3d(%rbx), %rsi # 48 8d 73 3d
/* ... */The problem with those previous techniques is that we are wasting too much bytes to get an address in a register. Could we avoid this step?
The answer is yes, if we exploit the system calls (page 73). Because when any syscall instruction is executed, the processor copy the next instruction’s address in the RCX register. This allows the kernel to come back where it’ve been called. Which means that, in our code, RCX always contains the address of the instruction following the previous executed syscall.
All we need then is to compute the relative address between the data and that instruction after the syscall. You could calculate this by ourselves but here is a way to make it easier with the help of objdump. Let’s start by writing the LEA instruction with a fake relative address (i.e. 0xff) then assemble this code with gas and finally look at it with objdump as follows (the useless parts have been redacted):
$ as -o http-01.o http-01.s
$ objdump -d http-01.o
[...]
0000000000000000 <_start>:
[...]
7: 0f 05 syscall
9: 50 push %rax
000000000000000a <bind>:
[...]
e: 48 8d 71 ff lea 0xff(%rcx),%rsi
[...]
000000000000003c <addr>:
[...]In the bind block, the lea instruction need to know the distance between the network address (at 0x3c) and the instruction following the previous syscall (the push at 0x09). The distance equals 0x3c - 0x09 = 0x33.
A similar calculation let us get the relative address of the message (at 0x58) to the instruction following the previous syscall (the push %rdi of the accept block, at 0x25). We then get 0x33 (it’s only a coincidence).
We then save 3 bytes per lea instruction without the need of adding supplementary instructions.
Final code
Here is the code when all the previous optimisation have been done:
.section .text
.globl _start
_start:
socket:
push $0x29 ; pop %rax # socket(
push $10 ; pop %rdi # AF_INET6,
pop %rsi # SOCK_STREAM,
# 0
syscall # ) ;
push %rax
bind:
push $49 ; pop %rax # bind(
pop %rdi # sockfd,
lea 0x33(%rcx), %rsi # *addr,
push $28 ; pop %rdx # addrlen
syscall # ) ;
listen:
push $50 ; pop %rax # listen(
# sockfd,
# backlog = 1
syscall # ) ;
loop:
accept:
push $43 ; pop %rax # accept(
# sockfd,
mov %ebp, %esi # *addr=0,
mov %ebp, %edx # *addrlen=0
syscall # ) ;
push %rdi
push %rax
sendto:
push $44 ; pop %rax # sendto(
pop %rdi # sockfd,
lea 0x33(%rcx), %rsi # buf,
push $0x28 ; pop %rdx # len,
# flags,
# dest_addr,
# addrlen
syscall # ) ;
close:
push $3 ; pop %rax # close(
# fd
syscall # ) ;
pop %rdi
jmp loop
addr:
.byte 0x0a, 0x00 # sin6_family = AF_INET6
.byte 0x1f, 0x90 # sin6_port = 8080
.byte 0, 0, 0, 0 # flowinfo
.byte 0, 0, 0, 0, 0, 0, 0, 0 # sin6_addr 1/2 = IN6ADDR_ANY_INIT
.byte 0, 0, 0, 0, 0, 0, 0, 0 # sin6_addr 2/2
.byte 0, 0, 0, 0 # sin6_scope_id
msg:
.ascii "HTTP/1.0 200 OK\r\n"
.ascii "Content-length: 2\r\n"
.ascii "\r\n"
.ascii "Ok"The next table summarize the previous sizes and add a column with our optimised version. We are shorter than the 32 bits version if we measure the instructions and data, but the full file is still longer than the 32 bits version.
| 32 bits & IPv4 | 64 bits & IPv6 | Optim. Code | |
|---|---|---|---|
| Default | 4756 | 5200 | 5088 |
| omagic & strip-all | 376 | 568 | 464 |
| Instructions & data | 142 | 236 | 128 |
Optimise the executable
File headers
Since it is the binary file size that matters most, and not the size of instructions and their data, we’ll now tackle the ELF file size. A bit like what’ve done ld when we’ve added the two options. But we’ll do this by hand, and a bit extreme.
The main idea is to create a minimal ELF header that’ll thus contain only one file header followed by only one program [section] header. The creation of this content is not complicated, you only need to follow the official documentation…
ELF Header
This first part of 40 bytes (that is 0x40 in hexadecimal) contains the fields that identifies the file as being an 64 bits executable ELF and other handfull details for the operating system. Amongst them: where it can find the sections headers.
Here is the content where we’ve put in comment the official field name followed by a short explanation or the value (depending on which is the most interesting in our case).
# https://refspecs.linuxbase.org/elf/gabi4+/ch4.eheader.html
.byte 0x7f, 'E', 'L', 'F' # ELF Signature
.byte 2 # EI_CLASS : 64 bits object
.byte 1 # EI_DATA : little endian
.byte 1 # EI_VERSION : 1
.byte 3 # EI_OSABI : Linux
.byte 0 # EI_ABIVERSION : 0
.fill 7, 1, 0 # EI_PAD : Padding
.2byte 2 # e_type : Executable
.2byte 62 # e_machine : AMD x86-64
.2byte 1, 0 # e_version : 1
.8byte 0x100078 # e_entry : Entry point
.8byte 0x40 # e_phoff : program table
.8byte 0 # e_shoff : section table
.4byte 0 # e_flags : no flags
.2byte 0x40 # e_ehsize : header's size
.2byte 0x38 # e_phentsize : program header's size
.2byte 1 # e_phnum : 1 program header
.2byte 0 # e_shentsize : section header's size
.2byte 0 # e_shnum : 0 section headers
.2byte 0 # e_shstrndx : section name tableMost of the fields don’t need any explanations because you only need to read the doc (and you then often only need to chose between the provided value the one you want). But the following fields seems usefull to be explained:
- e_entry : This is the entry point address in the software once it’ve been loaded in memory. This value depends on the text section’s address which is defined in the next part.
- e_phoff : program table’s address, relatively to the file. This header need 0x40 bytes and the table immediately follows this header.
- e_ehsize : This header’s size. You can measure it by yourselves, it takes 0x40 bytes.
- e_phentsize : Program header’s size (that is the size of each entry), this is the size of the following section.
Program section header
Without any surprise, the next data concern the program table, that is a list of headers describing the program sections. Here we only have one section and here is it’s value:
# https://refspecs.linuxbase.org/elf/gabi4+/ch5.pheader.html
.4byte 1 # p_type : Executable
.4byte 0x7 # p_flags : RWX
.8byte 0x78 # p_offset : offset in the file
.8byte 0x100078 # p_vaddr : virtual @ where to load this section
.8byte 0 # p_paddr : physical @ (useless here)
.8byte 0 # p_filesz : section size in the file
.8byte 0 # p_memsz : section size in memory
.8byte 0x100 # p_align : alignmentHere are the explanation of some of those fields:
- p_flags : tells the access right to give to the section in memory. We could ask only for reading and execution, but why not ask for everything ? (so we could use some self-modifying code…).
- p_offset : relative addres in the file toward the start of the data for this section. The first header takes 0x40 bytes, this one takes 0x38 and there is nothing more until the data. They can thus be found at 0x78 bytes from the file start.
- p_vaddr : Virtual address where to load the section data in memory. We can put almost anything we want. But not 0 because the kernel won’t appreciate and not a value too big because we’ve use it as the "number of waiting connexion in the queue" (cf. previous optimisations). We often find adress beginning at 0x400000 but we’ve chosen a smaller value here. Beware that this address must be aligned with the offset in the file (so the 0x78 at the end).
- p_filesz et p_memsz : give the size of this section (in the file and in memory) but those fields can equals zero (and the kernel take care of the computation of their values).
- p_align : value to use to align the previous offset and address.
You can measure it, this header is 0x38 bytes long.
Produce the binary file
To build the executable, we must copy those header just before the instructions and its datas. There is plenty of way to proceed: in assembly in one file, in multiple files, in hexadecimal, in binary,…
since we already have a makefile to produce our shellcodes, we’ve decided to separate the content in two files: one for the headers, one for the instructions and data. Both will be assembled with gas and we’ll then extract the binary content with objcopy. We finally concatenate them with cat. Here are the reciepes.
%.o: %.s
as $< -o $@
%.raw: %.o
objdump -j .text -O binary $< $@
%: header.raw %.raw
cat $^ > $@
chmod a+x $@It remains only to build the binary and measure its size.
$ make http
as -o http.o http.s
objcopy -j .text -O binary http.o http.raw
as -o header.o header.s
objcopy -j .text -O binary header.o header.raw
cat header.raw http.raw > http
chmod a+x http
rm http.o header.raw header.o
$ du -b http
248 httpWe’ve gone from 568 bytes to 248 bytes. It’s less than the 376 bytes of the 32 bits version (with IPv4). We could stop here but I wanted to go a little bit further…
Use the zero from uninitialised memory
This last optimisation exploit the fact that memory pages are initially filled by zeroes by the kernel before we can access them. If the file being loaded in memory ends with zeroes, there is no utility to copy them. And so there is no utility to write them in the file…
This is the case of our structure that contains the network address to listen to. Except the first 4 bytes that contains some values (2 bytes for the address family and 2 bytes for the port number), the remaining 24 bytes are all zeroes.
We can thus move this structure at the end of the file and only write the first 4 bytes. We won’t be able to tell gas to compute its size but it’s not a problem since this size if fixed (it alsways equals 28) and it was already hard coded when we replaced some mov with push/pop.
Here is how the end of the code looks like. The message is before the address. And the address have been truncated.
msg:
/* ... */
addr:
.byte 0x0a, 0x00 # sin6_family = AF_INET6
.byte 0x1f, 0x90 # sin6_port = 8080
# flowinfo
# sin6_addr 1/2 = IN6ADDR_ANY_INIT
# sin6_addr 2/2
# sin6_scope_idBeware: since the data have been moved, you must compute again the relative address used in the LEA instructions.
We can then build this new version of the binary file and measure its size. We get 224 bytes (24 less than the previous version). It’s even less than the optimised version in Github from which Akanoa build its own (it takes 229 bytes).
And after?
We won’t be able to shorten any part of this programm. The ELF header is already the smallest one and I don’t see any way to write an HTTP server with less instructions or datas. We could think of 224 bytes as being a kind of lowest limit to write such minimalistic server.
It’s indeed possible to make it smaller. But to do that, you should overlay parts of the program one over the other (which is called golfing). Some bytes will then have multiple meanings depending if they are read as an ELF header field, Programm Header fiels or an instruction to be executed. Each overlayed byte make the file shorter… This field is fascinating but this is a new story of its own.
Especially if you come back to the initial problem posed by Akanoa, nothing forced us to write a binary code:
Je veux [...] quelque chose qui réponde en HTTP le plus léger possible et qui a le moins de dépendance également.
Akanoa
If the aim is to get the smallest file with the least dependencies, any bash script is a way more suited. It avoid the dependency to the building chain, makes mores with less bytes and, using only Unix command, can be executed almost anywhere.
Here is an example of a minimalistic HTTP server in bash:
#!/bin/bash
while true ; do
echo -en "HTTP/1.0 200 OK\r\nContent-length: 2\r\n\r\nOk" \
| nc -l localhost 31337
doneIt takes only 120 bytes and we haven’t yet optimised it at all…